La Sfida
L'ente necessitava di un sistema automatizzato per identificare la presenza di targhe automobilistiche nelle immagini di veicoli usati, per garantire la privacy prima della pubblicazione online.
La Soluzione
Pipeline end-to-end di Machine Learning: web scraping automatizzato per la raccolta dati, annotazione manuale del dataset, estrazione features con HOG e classificazione binaria.
Il Risultato
Dataset di 184 immagini annotate, modello di classificazione funzionante e metodologia riproducibile per progetti di Computer Vision simili.
Il Contesto
Un ente di formazione necessitava di sviluppare un sistema per automatizzare il rilevamento della presenza di targhe automobilistiche nelle immagini di veicoli. L'obiettivo era creare una pipeline completa che potesse essere utilizzata come caso studio educativo e come base per applicazioni di privacy automation.
Le Sfide Principali
- Assenza di dataset: non esisteva un dataset pronto per il training specifico per questo use case
- Raccolta dati automatizzata: necessità di reperire immagini reali da fonti pubbliche
- Annotazione manuale: classificazione binaria delle immagini (targa presente/assente)
- Feature extraction: identificazione delle caratteristiche discriminanti per il modello
- Riproducibilità: pipeline documentata e riutilizzabile
L'Architettura
Pipeline End-to-End
Il progetto è stato strutturato in tre fasi distinte, ciascuna con obiettivi e output specifici:
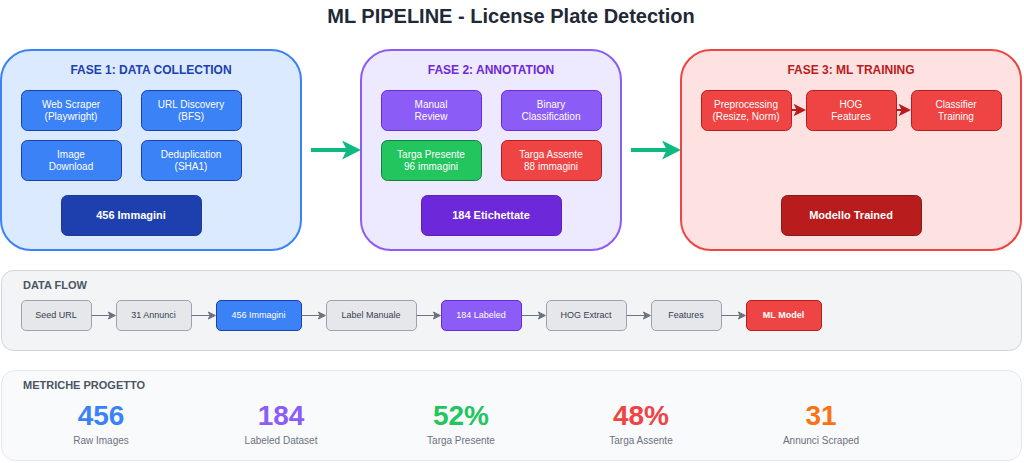
Fase 1: Data Collection
La raccolta dati è stata implementata con un web scraper automatizzato basato su Playwright:
| Componente | Tecnologia | Funzione |
|---|---|---|
| Browser Engine | Chromium Headless | Rendering pagine dinamiche |
| Automation | Playwright | Navigazione e interazione |
| URL Discovery | BFS Algorithm | Scoperta annunci correlati |
| Deduplication | SHA1 Hashing | Eliminazione duplicati |
Caratteristiche dello scraper:
- Navigazione breadth-first a partire da URL seed
- Gestione lazy loading tramite scroll automatico
- Simulazione click per caricare gallery complete
- Blocco ad network per performance
- Filtro dimensione minima immagini (60KB)
Fase 2: Data Annotation
Il dataset raccolto è stato annotato manualmente con classificazione binaria:
| Categoria | Descrizione | Immagini |
|---|---|---|
| Targa Presente | Veicoli con targa chiaramente visibile | 96 |
| Targa Assente | Veicoli senza targa o non visibile | 88 |
Criteri di annotazione:
- Visibilità completa o parziale della targa
- Esclusione immagini ambigue
- Bilanciamento delle classi (52% / 48%)
Fase 3: Feature Extraction & Training
Il modello di classificazione utilizza HOG (Histogram of Oriented Gradients) per l'estrazione delle features:
| Step | Operazione | Output |
|---|---|---|
| Preprocessing | Resize, normalizzazione, conversione colore | Immagini standardizzate |
| Feature Extraction | HOG descriptor | Vettori di features |
| Classification | Modello ML | Predizione binaria |
Stack Tecnologico
Data Collection Layer
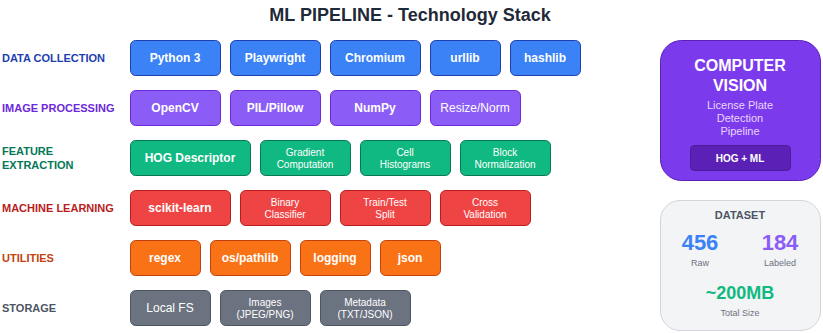
| Componente | Tecnologia | Configurazione |
|---|---|---|
| Runtime | Python 3 | Ambiente virtuale isolato |
| Browser Automation | Playwright | Chromium headless |
| HTTP Client | urllib | Download immagini |
| Hashing | hashlib | SHA1 per deduplication |
Machine Learning Layer
| Componente | Funzione |
|---|---|
| Image Processing | Preprocessing e normalizzazione |
| HOG Descriptor | Estrazione gradient features |
| Classifier | Modello di classificazione binaria |
Implementazione
Web Scraper
Lo scraper implementa un algoritmo BFS per la scoperta di annunci correlati:
Workflow di scraping:
- Partenza da URL seed (singolo annuncio)
- Estrazione URL annunci correlati dalla pagina
- Filtro regex per identificare solo annunci validi
- Download immagini con gestione lazy loading
- Deduplication tramite hash SHA1
- Salvataggio organizzato per annuncio
Ottimizzazioni implementate:
- Ad Blocking: intercettazione richieste verso ad network
- Viewport realistico: emulazione browser desktop
- User-Agent rotation: evitare detection
- Error handling robusto: continuità anche con errori parziali
Dataset Structure
L'organizzazione dei dati segue una struttura gerarchica:
| Directory | Contenuto | Dimensione |
|---|---|---|
| Raw Data | Immagini non processate per annuncio | ~119 MB |
| Annotated | Dataset etichettato per training | ~51 MB |
| Metadata | URL sorgente e riferimenti | < 1 MB |
Risultati e Metriche
Data Collection
| Metrica | Valore |
|---|---|
| Annunci processati | 31 |
| Immagini totali raccolte | 456 |
| Media immagini per annuncio | 14.7 |
| Dimensione dataset raw | 119 MB |
Dataset Annotato
| Metrica | Valore |
|---|---|
| Immagini annotate | 184 |
| Classe "targa presente" | 96 (52%) |
| Classe "targa assente" | 88 (48%) |
| Bilanciamento classi | Ottimale |
Performance Pipeline
| Metrica | Valore |
|---|---|
| Tempo scraping (31 annunci) | ~15 min |
| Throughput medio | ~2 annunci/min |
| Tasso successo download | > 95% |
Applicazioni
Use Cases
- Privacy Compliance: rilevamento automatico targhe per anonimizzazione
- Content Moderation: filtro immagini per piattaforme di annunci
- Fleet Management: analisi automatica immagini veicoli
- Insurance: verifica documentazione fotografica
Estensibilità
La pipeline può essere estesa per:
- OCR Integration: lettura caratteri targa dopo detection
- Multi-class: classificazione tipologia veicolo
- Real-time: processing stream video
- API Service: endpoint REST per inference
Lezioni Apprese
- Data quality > quantity: dataset bilanciato e ben annotato è fondamentale
- Playwright per scraping moderno: gestisce SPA e lazy loading nativamente
- HOG features: efficaci per detection oggetti strutturati come targhe
- Deduplication early: risparmiare storage e training time
- Documentazione pipeline: riproducibilità essenziale per progetti ML
- Annotazione manuale: tempo maggiore ma qualità superiore per dataset piccoli
Stack Tecnologico
Risultati in Numeri
"Il progetto ha dimostrato come sia possibile costruire una pipeline ML completa partendo da zero, dalla raccolta dati fino al modello funzionante."