La Sfida
Un gruppo di concessionarie auto necessitava di centralizzare i dati inventario provenienti da diversi sistemi DMS (Dealer Management System) in un catalogo nazionale unificato, mantenendo tracciabilità delle fonti e gestendo conflitti di dati.
La Soluzione
Pipeline ETL serverless con AWS Glue per l'elaborazione di file XML compressi da S3, trasformazione dati con pandas e persistenza su Aurora PostgreSQL, il tutto orchestrato con infrastruttura as code (SAM/CloudFormation).
Il Risultato
Sistema operativo che processa automaticamente i feed XML da multiple concessionarie, normalizza i dati in uno schema unificato e mantiene lo storico delle modifiche per fonte.
Il Contesto
Un gruppo di concessionarie auto operante a livello nazionale gestiva l'inventario veicoli attraverso diversi sistemi DMS (Dealer Management System). Ogni concessionaria utilizzava software differenti, generando dati in formati eterogenei che rendevano impossibile avere una visione unificata del catalogo disponibile.
Le Sfide Principali
- Dati frammentati: ogni concessionaria con proprio DMS e formato dati
- Formati eterogenei: XML con strutture diverse da normalizzare
- Tracciabilità: necessità di sapere quale fonte ha fornito ogni dato
- Conflitti: stesso veicolo presente in più fonti con dati discordanti
- Scalabilità: soluzione che cresca con il numero di concessionarie
- Costi: minimizzare spesa infrastrutturale con approccio serverless
L'Architettura
Pipeline ETL Serverless
L'architettura è stata progettata con un approccio completamente serverless su AWS:
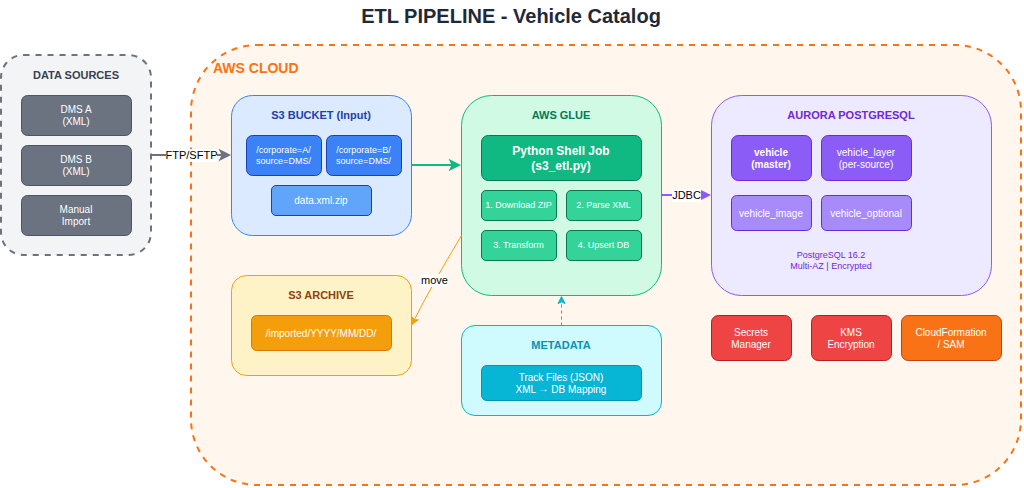
Flusso Dati
| Fase | Componente | Funzione |
|---|---|---|
| Ingestion | S3 Bucket | Ricezione file XML compressi da FTP |
| Processing | AWS Glue | ETL job Python per trasformazione |
| Storage | Aurora PostgreSQL | Database relazionale gestito |
| Archive | S3 Lifecycle | Archiviazione file processati |
Organizzazione S3
I file seguono una convenzione di naming strutturata:
s3://bucket/corporate={id}/source={DMS}/data.xml.zip
↓ (dopo elaborazione)
s3://bucket/imported/corporate={id}/source={DMS}/YYYY/MM/DD/HH/
Stack Tecnologico
AWS Services
| Servizio | Funzione | Configurazione |
|---|---|---|
| AWS Glue | ETL processing | Python Shell, 1 DPU |
| Aurora PostgreSQL | Database | 16.2, Multi-AZ ready |
| S3 | Object storage | Encryption KMS, lifecycle |
| Secrets Manager | Credentials | Rotation automatica |
| CloudFormation | IaC | SAM templates |
Python Stack
| Libreria | Versione | Utilizzo |
|---|---|---|
| pandas | 2.0.3 | Data manipulation |
| SQLAlchemy | 1.4.36 | ORM database |
| psycopg2 | 2.9.3 | PostgreSQL driver |
| xmltodict | 0.13.0 | XML parsing |
| boto3 | 1.21.21 | AWS SDK |
Data Model
Schema Database
Il modello dati gestisce la multi-sorgente con un pattern a layer:
| Tabella | Funzione |
|---|---|
| vehicle | Record master veicolo (1 per VIN) |
| vehicle_layer | Dati per fonte (N per veicolo) |
| vehicle_image | Immagini veicolo |
| vehicle_optional | Optional e accessori |
Gestione Multi-Source
Vehicle (master)
├── VehicleLayer (fonte: DMS_A)
├── VehicleLayer (fonte: DMS_B)
└── VehicleLayer (fonte: Manual)
Strategia conflitti: Last Writer Wins con audit trail completo.
Campi Principali Vehicle
| Campo | Tipo | Descrizione |
|---|---|---|
| external_source_id | VARCHAR | ID originale dal DMS |
| dealer_code | VARCHAR | Codice concessionaria |
| vin | VARCHAR | Vehicle Identification Number |
| make | VARCHAR | Marca veicolo |
| model | VARCHAR | Modello |
| version | VARCHAR | Versione/allestimento |
| list_price | DECIMAL | Prezzo di listino |
| promotional_price | DECIMAL | Prezzo promozionale |
| registration_date | DATE | Data immatricolazione |
| mileage | INTEGER | Chilometraggio |
ETL Job
Workflow di Elaborazione
Il job Glue Python Shell esegue le seguenti operazioni:
- Download: Scarica file ZIP da S3
- Decompress: Estrae XML dal file compresso
- Parse: Converte XML in dizionario Python
- Map: Applica mappatura campi da track file
- Transform: Normalizza e valida dati
- Compare: Confronta con dati esistenti (delta)
- Upsert: Inserisce o aggiorna database
- Archive: Sposta file in cartella processed
Track Files
I file di configurazione JSON definiscono il mapping XML → DB:
{
"root": "Ad",
"mappings": {
"Public/Brand": "make",
"Public/Model": "model",
"Business/ListPrice": "list_price",
"Codes/MakeCode": "make_code"
}
}
Mapping complessi supportati:
- 1 campo XML → N campi DB
- N campi XML → 1 campo DB (fallback)
- Nested structures (Images, Options)
Infrastructure as Code
SAM Template
L'intera infrastruttura è definita in CloudFormation/SAM:
| Resource | Template |
|---|---|
| KMS Key | Encryption S3 e database |
| S3 Bucket | Storage con lifecycle rules |
| Aurora Cluster | PostgreSQL managed |
| Glue Job | ETL Python Shell |
| Bastion Host | Accesso sicuro DB |
| Security Groups | Network isolation |
Deployment
# Prima installazione
sam build -cup && sam deploy --guided
# Deploy successivi
sam build -cup && sam deploy --config-env prod
# Cleanup
sam delete --config-env prod
Multi-Environment
Configurazione per ambienti multipli via samconfig.toml:
| Environment | Region | Scopo |
|---|---|---|
| poc | eu-west-1 | Proof of Concept |
| staging | eu-central-1 | Test integrazione |
| prod | eu-central-1 | Produzione |
Sicurezza
Encryption
| Layer | Metodo |
|---|---|
| S3 | KMS encryption at rest |
| Aurora | KMS encryption + SSL in transit |
| Secrets | AWS Secrets Manager |
| Network | VPC isolation |
Accesso Database
L'accesso ad Aurora avviene esclusivamente tramite:
- Bastion Host EC2 con SSH tunneling
- Glue Connection via JDBC interno VPC
- Secrets Manager per credenziali (no hardcoding)
Sviluppo Locale
Docker Compose
Per testing locale senza AWS:
services:
python:
build: .
volumes:
- ./scripts:/app
postgres:
image: postgres:16-alpine
environment:
POSTGRES_DB: vehicles
Testing
# Setup ambiente
python3 -m venv .env
source .env/bin/activate
pip install -r requirements.txt
# Esecuzione locale
python s3_etl.py --local --file test.xml.zip
Risultati
Performance
| Metrica | Valore |
|---|---|
| Tempo elaborazione file | ~30 sec/file |
| Throughput | 1000+ veicoli/minuto |
| Costo Glue job | ~$0.44/ora (1 DPU) |
| Storage S3 | Pay per use |
Benefici
- Zero server da gestire: architettura 100% serverless
- Scalabilità automatica: Glue scala con il carico
- Costi ottimizzati: paghi solo per l'uso effettivo
- Tracciabilità completa: ogni dato ha la sua fonte
- Disaster recovery: backup automatici Aurora 35 giorni
- IaC: infrastruttura versionata e riproducibile
Lezioni Apprese
- Glue Python Shell: ideale per job ETL leggeri (< 1 DPU sufficiente)
- Track files: configurazione esterna permette nuovi DMS senza codice
- Layer pattern: gestire multi-source senza perdere dati
- SAM templates: nested stacks per modularità
- Local testing: Docker Compose essenziale per sviluppo rapido
- Secrets Manager: mai credenziali in codice o variabili ambiente
Stack Tecnologico
Risultati in Numeri
"La pipeline ci permette di avere una visione unificata dell'inventario veicoli di tutte le concessionarie, con dati sempre aggiornati e tracciabilità completa delle fonti."