La Sfida
L'azienda necessitava di una piattaforma centralizzata per raccogliere, elaborare e analizzare i dati telemetrici di una flotta di migliaia di veicoli, con requisiti stringenti di scalabilità, real-time processing e compliance GDPR.
La Soluzione
Architettura cloud-native su AWS con Data Lake in pattern Medallion, ingestion dual-channel (HTTP + Kafka), processing serverless e piattaforma ML integrata per analytics predittiva.
Il Risultato
Piattaforma in grado di processare oltre 10 milioni di eventi giornalieri con latenza sub-secondo, costi operativi ottimizzati e time-to-insight ridotto da giorni a minuti.
Il Contesto
Un importante operatore nel settore della logistica e fleet management gestiva una flotta di migliaia di veicoli commerciali. I dati telemetrici (GPS, consumi, diagnostica) venivano raccolti da sistemi eterogenei e archiviati in silos separati, rendendo impossibile una visione unificata delle operazioni.
Le Sfide Principali
- Dati frammentati: informazioni distribuite su più sistemi legacy non integrati
- Scalabilità limitata: l'infrastruttura on-premise non reggeva i picchi di traffico
- Latenza elevata: i report richiedevano giorni per essere generati
- Costi crescenti: manutenzione hardware e licensing in aumento costante
- Compliance: necessità di garantire GDPR e audit trail completo
L'Architettura
Flusso Dati End-to-End
La piattaforma è stata progettata seguendo un'architettura a quattro layer:
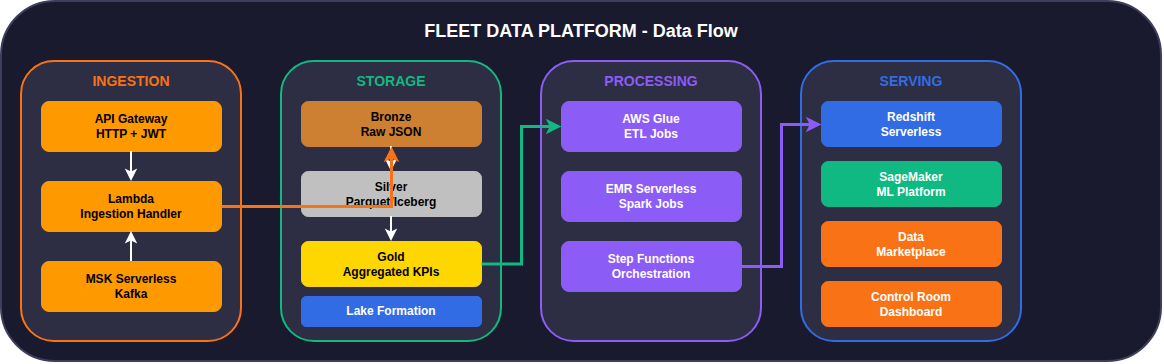
1. Ingestion Layer - Dual Channel
La piattaforma supporta due canali di ingestion paralleli per massima flessibilità:
| Canale | Tecnologia | Casi d'Uso |
|---|---|---|
| HTTP API | API Gateway + Lambda | Sistemi moderni, telematica HTTP |
| Kafka | MSK Serverless | High-throughput, sistemi legacy |
Entrambi i canali convergono sulla stessa logica di elaborazione Lambda, garantendo consistenza nel trattamento dei dati.
2. Data Lake - Medallion Architecture
I dati vengono organizzati su S3 seguendo il pattern Medallion Architecture:
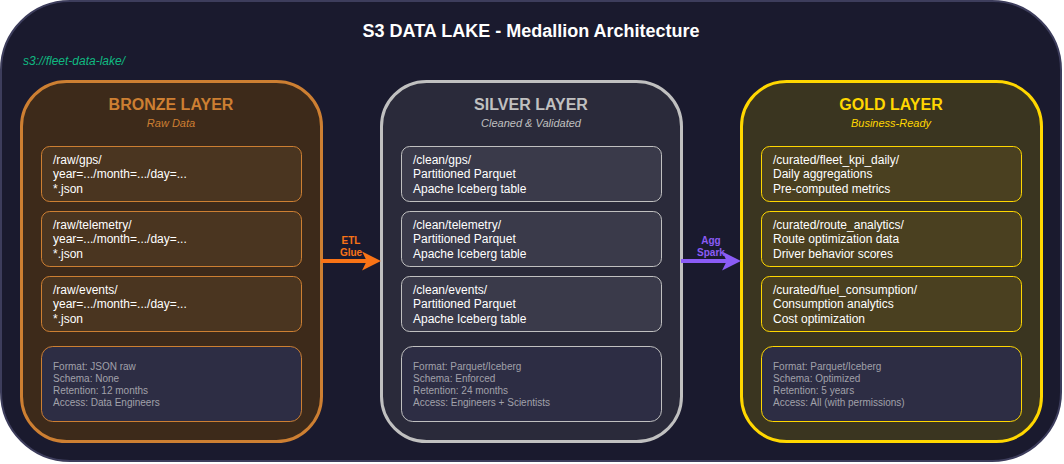
| Layer | Formato | Retention | Accesso |
|---|---|---|---|
| Bronze | JSON raw | 12 mesi | Data Engineers |
| Silver | Parquet/Iceberg | 24 mesi | Engineers + Scientists |
| Gold | Parquet/Iceberg | 5 anni | Tutti (con permessi) |
3. Processing Layer
La trasformazione dei dati avviene tramite servizi serverless:
- AWS Glue: ETL batch per trasformazioni Bronze → Silver
- EMR Serverless: Job Spark complessi e ML feature engineering
- Step Functions: Orchestrazione workflow multi-step con branching condizionale
4. Serving Layer
I dati elaborati vengono esposti attraverso quattro canali:
- Data Marketplace: API REST per data products B2B
- Control Room: Dashboard real-time per fleet manager
- Redshift Serverless: Query OLAP per analytics
- SageMaker: ML training e inferenza
Scelte Tecnologiche Chiave
Apache Iceberg per il Data Lake
Abbiamo adottato Apache Iceberg come table format per il Silver e Gold layer:
- ACID Transactions: consistenza garantita anche con write concorrenti
- Time Travel: possibilità di query su snapshot storici
- Schema Evolution: modifiche schema senza riscrittura dati
- Partition Evolution: cambio strategia di partizionamento a caldo
Governance con Lake Formation
AWS Lake Formation gestisce la governance centralizzata:
- Accesso fine-grained a livello colonna/riga
- Tag-based access control per multi-tenancy
- Audit trail completo di tutti gli accessi
- Integrazione nativa con Glue Catalog
Autenticazione Multi-Layer
| Componente | Metodo | Scopo |
|---|---|---|
| API Ingestion | JWT (Keycloak) | M2M authentication |
| Data Marketplace | OAuth2 (Cognito) | User authentication |
| Control Room | SSO (Keycloak) | Employee access |
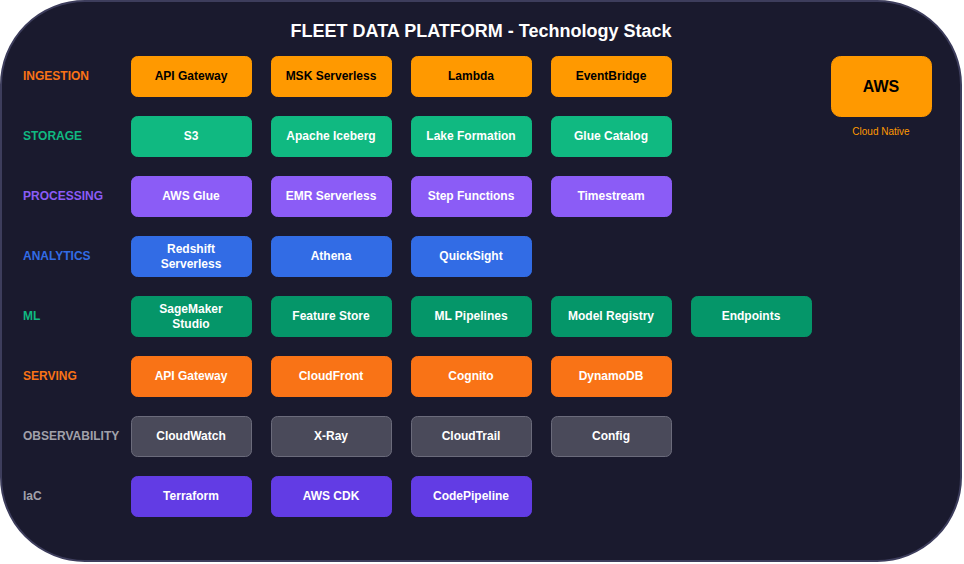
Stack Tecnologico Completo
Risultati e Benefici
Performance
| Metrica | Prima | Dopo |
|---|---|---|
| Latenza ingestion | 5-10 secondi | < 1 secondo |
| Tempo generazione report | 2-3 giorni | < 5 minuti |
| Capacità eventi/giorno | 500K | 10M+ |
| Downtime mensile | 4-8 ore | < 5 minuti |
Costi Operativi
La migrazione a serverless ha portato significativi risparmi:
- ~60% riduzione rispetto all'infrastruttura on-premise precedente
- Pay-per-use: nessun costo per risorse inutilizzate
- Auto-scaling: gestione automatica dei picchi senza over-provisioning
- Zero manutenzione: AWS gestisce patching, backup e HA
Business Value
- Real-time visibility: dashboard live per tracking flotta
- Predictive maintenance: modelli ML per prevenzione guasti
- Route optimization: analytics per ottimizzazione percorsi
- Fuel efficiency: analisi consumi per riduzione costi carburante
- Compliance: audit trail completo per GDPR
Lezioni Apprese
- Serverless-first: privilegiare sempre servizi gestiti per ridurre operational overhead
- Medallion Architecture: pattern efficace per organizzare data lake di grandi dimensioni
- Iceberg: table format essenziale per data lake enterprise con requisiti ACID
- Lake Formation: semplifica enormemente la governance multi-tenant
- Step Functions: orchestrazione visuale riduce complessità delle pipeline
- IaC from day one: Terraform ha permesso ambienti riproducibili e disaster recovery rapido
Stack Tecnologico
Risultati in Numeri
"La nuova piattaforma ci ha permesso di passare da report settimanali a insight in tempo reale. Ora possiamo ottimizzare le rotte e prevenire i guasti prima che accadano."